June 12, 2025
5 Min Read
Part 3 - Multilayered Governance - Mitigating Prompt Injection Threats

Madan Singhal
Head of AI

Prompt injection attacks exploit how generative AI Large Language Models (LLMs) interpret input, enabling malicious actors to manipulate model behavior to achieve a wide range of malicious outcomes. Given current LLM architectures, preventing prompt injection entirely is extremely difficult. As a result, effective mitigation demands a contextual security strategy—one that includes governance, continuous monitoring, and adaptive controls.
- Part 1 - explored different types of emerging prompt injection threats
- Part 2 - provided specific attack examples and industry scenarios
- This Part 3 - outlines a context-aware, layered defense strategy to detect threats, limit exposure, and reduce impact.
Security experts and organizations like OWASP and NIST agree: with current architectures, LLMs cannot reliably distinguish between trusted system instructions and untrusted user input. This opens the door to prompt injection, where carefully crafted inputs hijack the model’s attention and cause unwanted AI behavior.
Attackers continue to evolve their techniques using obfuscation, encoding tricks, payload splitting, and exploiting the model’s helpful nature. Traditional defenses like blacklists or keyword filtering are ineffective against these adaptive methods.
Mitigating prompt injection requires deeper semantic understanding. Defenses must analyze prompts in the context of the user’s identity and permissions, the AI application’s role and configuration, the nature of the underlying data, and real-time signals like data sensitivity or access patterns.
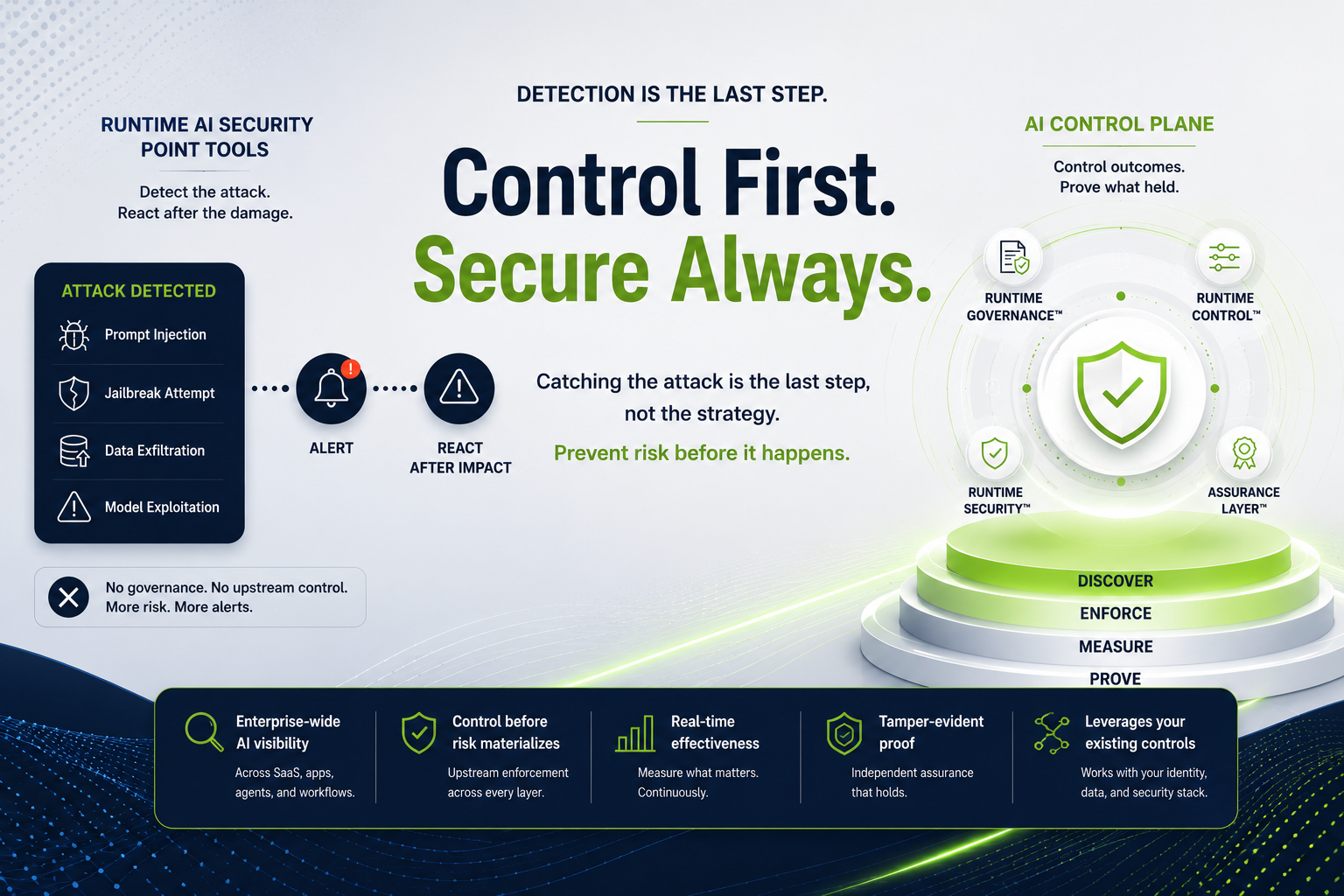
Contextual security—an approach rooted in Zero Trust, behavioral analytics, and dynamic access control is key to mitigating threats. A robust defense must treat prompt injection as a context-sensitive risk and incorporate a control plane with full visibility and governance that spans all AI systems and environments.
No single technique can stop all prompt injection attacks. A defense-in-depth strategy addresses the issue across four levels:
Secure prompt data before it reaches the model.
Shape the LLM’s behavior to resist injection.
Monitor and control AI outputs at runtime.
Establish enterprise-grade governance oversight.
Singulr AI delivers an enterprise-grade governance and security platform designed to manage and protect all GenAI interactions. The platform supports innovation while minimizing shadow AI risk, protecting sensitive data, streamlining audit and compliance, and defending against prompt injection threats.
Since prompt injection cannot be fully eliminated at the model level, Singulr AI provides a contextual AI control plane to protect all AI activity including both agentic and human interactions.
Prompt injection is a persistent and evolving threat that demands a layered defense strategy spanning inputs, models, outputs, and system operations.
Singulr AI enables organizations to implement these defenses holistically. With Continuous Discovery, contextual risk scoring, and runtime enforcement, enterprises can stay ahead of threats while confidently accelerating.
Request a demo to learn how Singulr AI can help you get ahead and stay ahead of this evolving threat.
Complete visibility across all three AI vectors in your environment, including agents and embedded SaaS AI
Singulr Pulse™ intelligence and the live risk signals that feed your control plane
Continuous red teaming, identifying control gaps and vulnerabilities in real time
Singulr Runtime Control™ enforcing governance intent without slowing innovation