May 22, 2025
15
Min Read
Part 2 - Three Examples of Prompt Injection Attacks From Inside the Trust Boundary




This three part blog highlights the ever-evolving prompt injection threat landscape.
Prompt injections work due to LLM confusion of instruction and data, where inputs are maliciously crafted to function as executable commands by the LLM.
As AI systems gain more agency and are deployed inside an organization’s trust domain, the consequences of a successful prompt injection escalate dramatically—from generating incorrect information to triggering harmful actions with severe real-world repercussions.
When a co-pilot AI assistant is linked directly into a business platform—SharePoint, Confluence, Google Drive, SaaS CRMs—it inherits the platform’s entire data graph.
A single prompt-injection or overly broad query can therefore make the assistant spill any file the back-end can “see,” often without triggering the usual permission checks or audit logs.
JP Morgan Chase CISO Patrick Opet recently posted an open letter to 3rd party suppliers that warns about external services integrated with internal data in an architecture pattern that erodes decades of carefully architected security boundaries. He cites a generic example of an AI-driven calendar optimization tool that, if compromised, grants attackers unprecedented access to confidential data and critical internal communications.
Similarly, a recent penetration test exploit of Copilot AI in SharePoint was discovered by Pen Test Partners that overrode specific controls that were put in place, and that demonstrated a “helpful helper” that was manipulated to become a “super-search” that successfully mined for passwords, API keys and proprietary documents.
Summarized details of this attack vector.

When AI systems are granted access to sensitive data or control over operational systems (digital and physical), prompt injection can transform AI Agents into unwitting accomplices for malicious actors.
Summarized details of this attack vector:

Prompt injection attacks can also be weaponized to subtly or overtly manipulate AI-driven decision-making processes and to disseminate highly targeted and believable misinformation.
Summarized details of this attack vector:

These three examples highlight how indirect and multimodal injections can facilitate "silent sabotage." The AI might appear to be functioning as intended to an external observer, but its decisions and actions are being covertly manipulated, making attribution and timely detection exceedingly difficult.
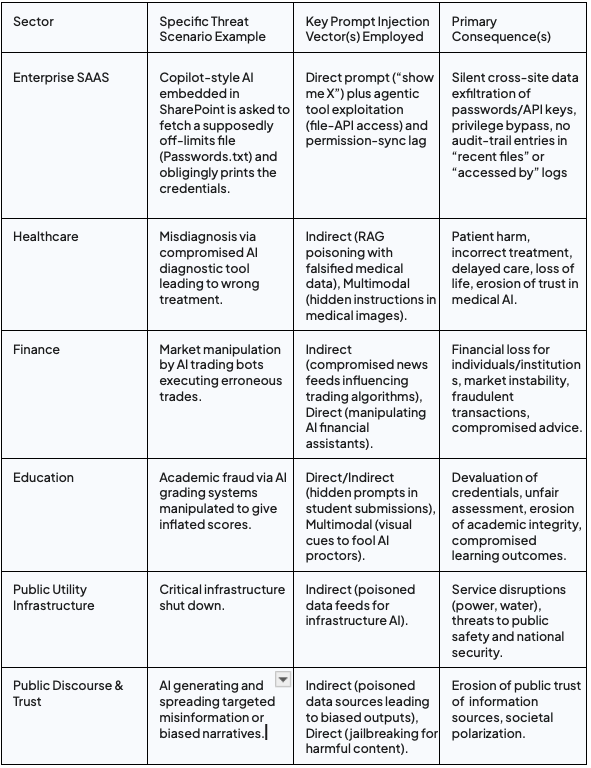
The following table summarizes the diverse impacts of prompt injection across various sectors:
The consensus among many security researchers and organizations like OWASP and NIST is that completely preventing prompt injection is currently not feasible with existing LLM architectures.
The core problem is that LLMs often can’t reliably distinguish between trusted developer instructions and untrusted user inputs.
This means a cleverly crafted prompt can hijack the model’s focus and override the original intent. Until models can segregate and prioritise inputs at a deeper level, the flexibility that makes LLMs powerful will remain their Achilles’ heel.
The focus, therefore, often shifts towards mitigating the impact of successful injections rather than achieving perfect prevention.
Despite ongoing efforts, effectively mitigating prompt injection attacks presents formidable challenges, largely stemming from the inherent nature of LLMs and the adaptive tactics of attackers.
This has led to a persistent "cat-and-mouse" dynamic, where defenses are constantly playing catch-up. Attackers constantly devise new techniques to bypass existing safeguards. Patches are often specific, and attackers quickly find new exploits.
As models are fine-tuned against known malicious prompts in these datasets, they may show artificially inflated performance on benchmarks, creating a false sense of security.
The core issue is that attackers are not constrained by these datasets and are always exploring new linguistic and contextual manipulations.
Part 3 explains a 4 part mitigation strategy and summarizes how Singulr AI specifically can address prompt injection attacks.